Appearance
What is Vertex AI and Gemini AI?
What is Vertext AI
Vertex AI is a fully-managed, unified AI development platform for building and using generative AI.
Integrate Gemini on Vertex AI with Firebase SDKs in iOS apps
Step1: Set up "Build with Gemini" in your Firebase project
- In the Firebase console, go to the Build with Gemini page.
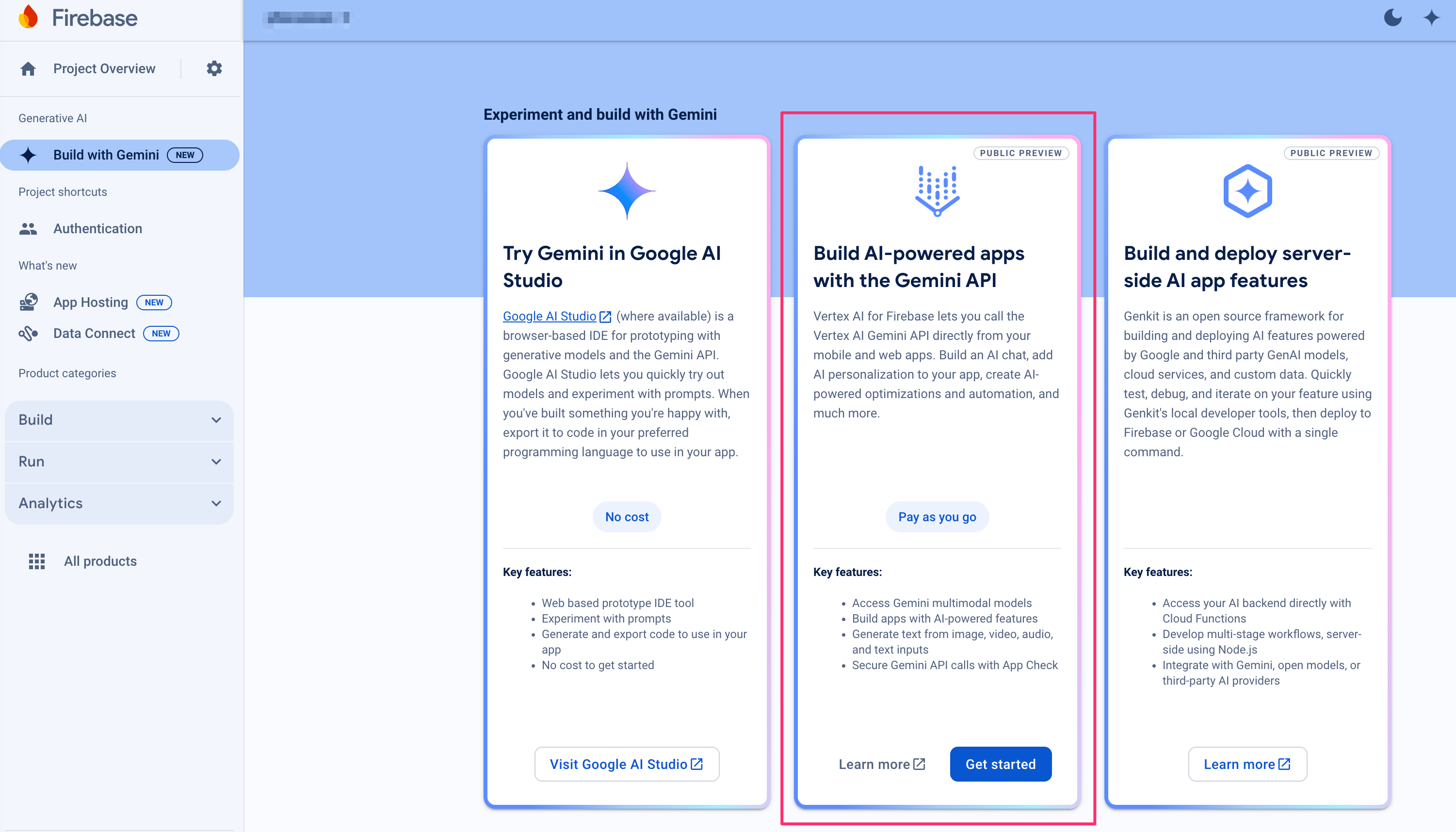
Click the second card - Build AI-powered apps with the Gemini API to do the following tasks.
- Upgrade your project to use the
Blaze pay-as-you-gopricing plan. - Enable the following two APIs for your project:
aiplatform.googleapis.comandfirebaseml.googleapis.com
- Upgrade your project to use the
Continue to the next step in this guide to add the SDK to your app.
Step2: Add the FirebaseVertexAI-Preview Library in the Firebase SDK
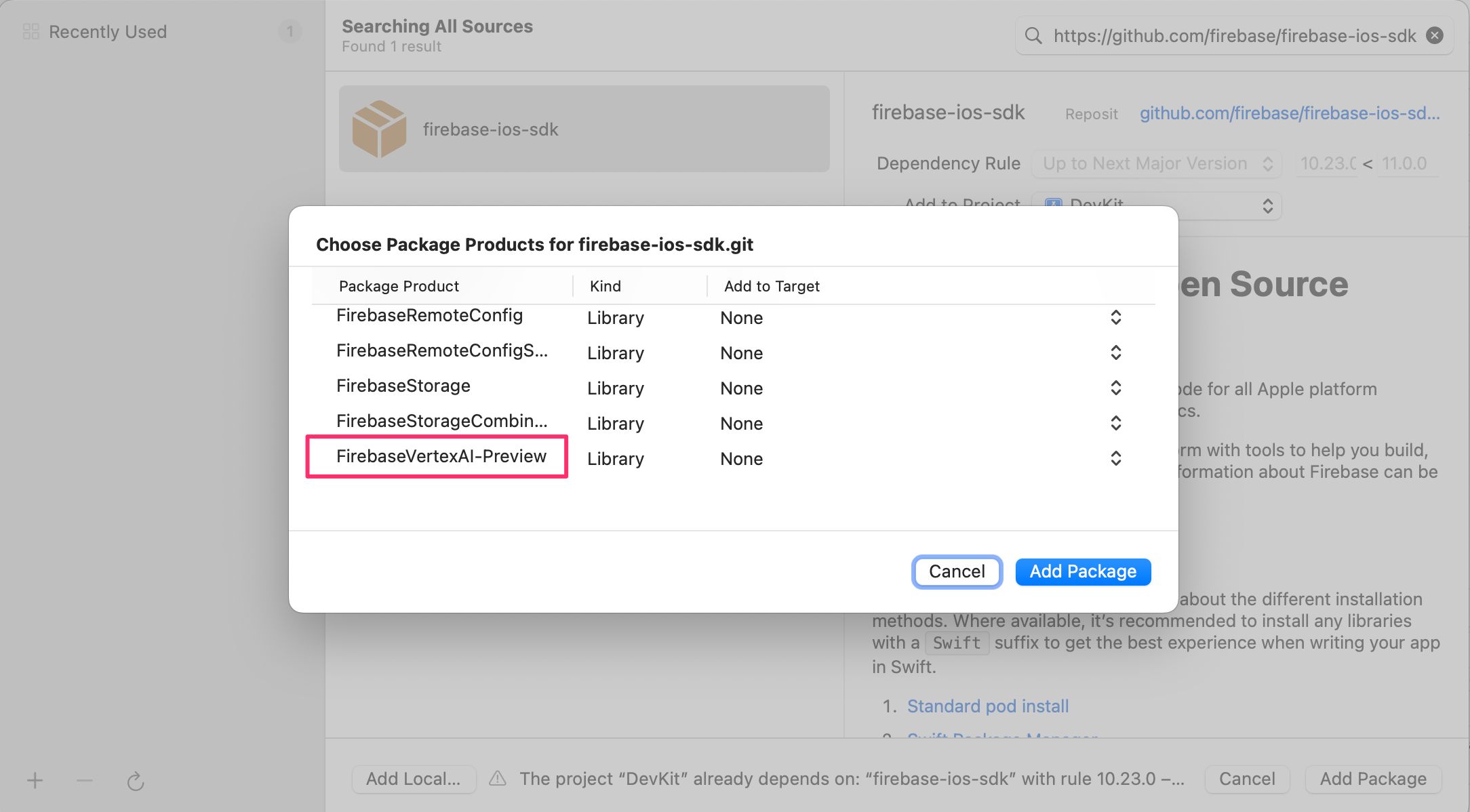
- In Xcode, with your app project open, navigate to File > Add Package Dependencies.
- Input the Firebase SDK repository:
https://github.com/firebase/firebase-ios-sdkand click Add Package. - Select the FirebaseVertexAI-Preview library anc click Add Package.
Step3: Call the Vertex AI Gemini API
swift
import FirebaseVertexAI
// Initialize the Vertex AI service
let vertex = VertexAI.vertexAI()
// Initialize the generative model with a model that supports your use case
// Gemini 1.5 models are versatile and can be used with all API capabilities
let model = vertex.generativeModel(modelName: "gemini-1.5-flash-preview-0514")
// Provide a prompt that contains text
let prompt = "Write a story about a magic backpack."
// To generate text output, call generateContent with the text input
let response = try await model.generateContent(prompt)
if let text = response.text {
print(text)
}Gemini on Vertex AI Available models
- Gemini 1.5 Flash
- gemini-1.5-flash-001
- gemini-1.5-flash
- gemini-1.5-flash-preview-0514
- Gemini 1.5 Pro
- gemini-1.5-pro-001
- gemini-1.5-pro
- gemini-1.5-pro-preview-0514
- gemini-1.5-pro-preview-0409
- Gemini 1.0 Pro Vision
- gemini-1.0-pro-vision-001
- gemini-1.0-pro-vision
- Gemini 1.0 Pro
- gemini-1.0-pro-002
- gemini-1.0-pro-001
- gemini-1.0-pro
Gemini on Vertex AI Prices
| Model | Price (=< 128K conext window) | Price (> 128K conext window) |
|---|---|---|
| Gemini 1.5 Flash | Text Input: $0.000125 / 1k characters Text Output: $0.000375 / 1k characters | Text Input: $0.00025 / 1k characters Text Output: $0.00075 / 1k characters |
| Gemini 1.5 Pro | Text Input: $0.00125 / 1k characters Text Output: $0.00375 / 1k characters | Text Input: $0.0025 / 1k characters Text Output: $0.0075 / 1k characters |
| Gemini 1.0 Pro | Text Input: $0.000125 / 1k characters Text Output: $0.000375 / 1k characters |
Gemini on Vertex AI available regions
Google Cloud uses regions to define regional APIs. Google Cloud only stores customer data in the region that you specify for all generally-available features of Generative AI on Vertex AI.
Generative AI on Vertex AI is available in the following regions:
- United States(7)
- Dallas, Texas (us-south1)
- Iowa (us-central1)
- Moncks Corner, South Carolina (us-east1)
- Northern Virginia (us-east4)
- Columbus (us-east5)
- Oregon (us-west1)
- Las Vegas, Nevada (us-west4)
- Canada(1)
- Montréal (northamerica-northeast1)
- South America(1)
- Sao Paulo, Brazil (southamerica-east1)
- Asia Pacific(7)
- Changhua County, Taiwan (asia-east1)
- Hong Kong, China (asia-east2)
- Mumbai, India (asia-south1)
- Singapore (asia-southeast1)
- Sydney, Australia (australia-southeast1)
- Tokyo, Japan (asia-northeast1)
- Seoul, Korea (asia-northeast3)
- Europe(10)
- Belgium (europe-west1)
- London, United Kingdom (europe-west2)
- Frankfurt, Germany (europe-west3)
- Netherlands (europe-west4)
- Zürich, Switzerland (europe-west6)
- Milan, Italy (europe-west8)
- Paris, France (europe-west9)
- Finland (europe-north1)
- Madrid, Spain (europe-southwest1)
- Warsaw, Poland (europe-central2)
- Middle-East(1)
- Tel Aviv, Israel (me-west1)
Model parameters
Top-K
Top-K changes how the model selects tokens for output.
A top-K of 1 means the next selected token is the most probable among all tokens in the model's vocabulary (also called greedy decoding), while a top-K of 3 means that the next token is selected from among the three most probable tokens by using temperature.
For each token selection step, the top-K tokens with the highest probabilities are sampled. Then tokens are further filtered based on top-P with the final token selected using temperature sampling.
Specify a lower value for less random responses and a higher value for more random responses.
Top-P
Top-P changes how the model selects tokens for output.
Tokens are selected from the most (see top-K) to least probable until the sum of their probabilities equals the top-P value.
For example, if tokens A, B, and C have a probability of 0.3, 0.2, and 0.1 and the top-P value is 0.5, then the model will select either A or B as the next token by using temperature and excludes C as a candidate.
Specify a lower value for less random responses and a higher value for more random responses.
Temperature
The temperature is used for sampling during response generation, which occurs when topP and topK are applied.
Temperature controls the degree of randomness in token selection. Lower temperatures are good for prompts that require a less open-ended or creative response, while higher temperatures can lead to more diverse or creative results.
A temperature of 0 means that the highest probability tokens are always selected. In this case, responses for a given prompt are mostly deterministic, but a small amount of variation is still possible.
If the model returns a response that's too generic, too short, or the model gives a fallback response, try increasing the temperature.
Valid parameter values
| Parameter | Gemini 1.0 Pro Vision | Gemini 1.5 Pro | Gemini 1.5 Flash |
|---|---|---|---|
| Top-K | 1 - 40 (default 32) | Not supported | Not supported |
| Top-P | 0 - 1.0 (default 1.0) | 0 - 1.0 (default 0.95) | 0 - 1.0 (default 0.95) |
| Temperature | 0 - 1.0 (default 0.4) | 0 - 2.0 (default 1.0) | 0 - 2.0 (default 1.0) |
References
- Get started with the Gemini API using the Vertex AI for Firebase SDKs
- Generate text from text-only prompts using the Gemini API
- Generate text from multimodal prompts using the Gemini API
- Build multi-turn conversations (chat) with the Gemini API
- Send multimodal prompt requests
- Learn about the Gemini models
- Build multi-turn conversations (chat) with the Gemini API
- Vertex AI pricing
- Generative AI on Vertex AI locations
- Vertex AI Console